
[breadcrumb]
 If this condition exists action is required to restore sanity as quickly as possible!
If this condition exists action is required to restore sanity as quickly as possible!
 You might then need to double check Distributed Replication Block Device or DRBD meta data for corruption if the servers do not sync up. This DRBD is what synchronizes data between the two servers. Check the status as described above and if you see the DRBD error, then run the command utils service database drbd force-keep-node which will reset the DRBD and set the server to Secondary/Inactive.
Ah life in the world of HA!
You might then need to double check Distributed Replication Block Device or DRBD meta data for corruption if the servers do not sync up. This DRBD is what synchronizes data between the two servers. Check the status as described above and if you see the DRBD error, then run the command utils service database drbd force-keep-node which will reset the DRBD and set the server to Secondary/Inactive.
Ah life in the world of HA!
What is a High Availability Server Configuration?
HA availability server configuration often results from the sharing of a database between two servers. One server is Primary or Active, and the other server is Secondary or Inactive. Generally in the case of Voice Mail servers or Contact Center servers, there is a shared trunk group that interconnects the iPBX or Call Manager to the Active Server. Should that server fail, the call searches through the trunk group ultimately connecting with the Secondary Server which has now taken on the Primary or Active Roll. In the case of the Contact Center both ShoreTel and CISCO use this strategy with great results.Is it “alive”?
A condition known as “Split Brain” can result, however, causing both servers to get “confused”. This is generally the result of one of three conditions: a server loses power or becomes disconnected from the network during a database replication between the servers; or one of the servers actually restarts during the database replication process. When this happens database updates to each server may not be replicated to the other server and we get a Split Brain. The first step in remediation to to recognize the condition! It may not be readily identifiable. In the case of CISCO you can log into the server through the CLI and run utils service database status which will show the present condition of both servers. If you see the status “connection status unknown” or “Primary/Unknown” or “Secondary/Unknown” you are now in a schizophrenic mode! Both servers are up and operational but neither server is processing calls as neither server knows that it is the Primary server! Bad things are happening!
If this condition exists action is required to restore sanity as quickly as possible!
Split Brain surgery!
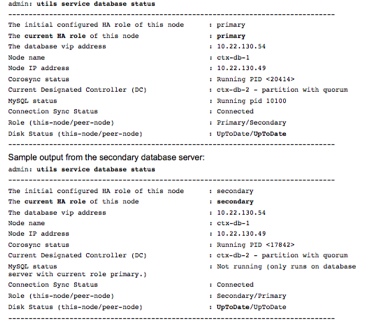
The remediation can be summarized as restoring each server to a role, Primary/Active and Secondary/Inactive. Once that is established you will need to pick which database is most current, and then copy it to the other server, restoring synchronization. Again CISCO has tools to assist with this process and if followed, this surgery can go smoothly and quickly! Basically log into the CLI of the server that has the data you want to keep and run the command utils service database status . Then log into the other server and run the command utils service database drbd discard-node which should restore database replication to normal. Then run the command utils service database status and you should see something that looks like this:
You might then need to double check Distributed Replication Block Device or DRBD meta data for corruption if the servers do not sync up. This DRBD is what synchronizes data between the two servers. Check the status as described above and if you see the DRBD error, then run the command utils service database drbd force-keep-node which will reset the DRBD and set the server to Secondary/Inactive.
Ah life in the world of HA!